







KI-(Künstliche Intelligenz)-Projekte richtig aufsetzen
Künstliche Intelligenz – KI (oder AI für Artificial Intelligence) ist das Schlagwort, dass derzeit durch alle Medien rauscht, große Potenziale für Unternehmen verspricht und als Technologie der Zukunft gepriesen wird. Von dem Spielen einer Schlüsselrolle für die Industrie in Deutschland ist gar die Rede. Die Verfügbarkeit von kostengünstiger hoher Rechenleistung zusammen mit der Möglichkeit der nahezu unbegrenzten Speichermöglichkeit großer Datenmengen bietet heute die Grundlage für die Verarbeitungsgeschwindigkeit, die für KI erforderlich ist. Und die Rechenleistung wird künftig weiter steigen. Zwischenzeitlich werden Hardwarekomponenten speziell für KI-Aufgaben entwickelt und bereits eingesetzt.
Liegt schon der Hintergrund zu KI für viele noch etwas im nebulösen, wird die Antwort auf die Frage wie eigentlich solche Projekte aufgesetzt werden oder wie man damit beginnen soll noch verschwommener.
Hintergrund zu KI richtig verstehen und einordnen
Begriffseinordnung
Künstliche Intelligenz: Künstliche Intelligenz befasst sich mit der Nachbildung bestimmter Sachverhalte menschlicher Intelligenz auf Computersystemen. Dazu gehören u.a. die Erkennung von Sprache, kreatives Verhalten, Problemlösung, Mustererkennung, Fähigkeit aus Erfahrung zu lernen und Schlussfolgerungen aus unvollständigen Informationen zu ziehen. KI-Lösungen verifizieren ihre Entscheidungen im Nachgang und entwickeln so einen soliden Erfahrungsschatz. Dadurch können immer bessere Lösungen entwickelt und Vorhersagen getroffen werden.
Machine Learning: Ist ein sehr wichtiges Teilgebiet der künstlichen Intelligenz. Maschinelles Lernen ist ein Oberbegriff für die „künstliche“ Generierung von Wissen aus Erfahrung: Ein künstliches System lernt aus Beispielen, kann Muster sowie Gesetzmäßigkeiten erkennen und kann diese nach Beendigung der Lernphase verallgemeinern (Quelle: Wikipedia).
Ein Computermodell analysiert dazu mit Hilfe selbstlernender Algorithmen (mathematische und statistische) große Mengen an Daten (u.a. Trainingsdaten). Das Modell versucht nun diese Daten intelligent zu verknüpfen, Zusammenhänge zu ermitteln, Schlussfolgerungen zu ziehen, um damit Vorhersagen treffen zu können.
Überwachtes Lernen (Supervised Learning): Eine Variante des maschinellen Lernens.
Dabei werden für das Trainieren des Systems gegebene Paare von Ein- und Ausgabedaten herangezogen. Zu jedem Eingabewert gehört ein bekannter Ausgabewert. Das Lernen erfolgt durch die Bereitstellung des korrekten Ausgabewerts, der zu einer Eingabe gehört. Nach mehreren Rechenläufen mit unterschiedlichen Ein- und Ausgabedaten wird dem System die Fähigkeit antrainiert, Verknüpfungen und Beziehungen herzustellen. Algorithmen wie z.B. Regression sind hier im Einsatz.
Unüberwachtes Lernen (Unsupervised Learning): Eine weitere Variante des maschinellen Lernens.
Beim unüberwachten Lernen kennt das System noch keine Eingaben, sondern es erstellt ein Modell, dass die Eingaben beschreibt, Muster sowie verborgene Strukturen erkennt und dies eigenständig in Klassen/Kategorien einteilt. Hier spielen Algorithmen wie Clustering/Clusteranalyse (u.a. K-Means) und Reduzierung der Dimensionalität eine Rolle.
Künstliche Neuronale Netze: Künstliche Neuronale Netze nehmen Anleihe am Aufbau des menschlichen Gehirns und sind von dessen biologischen Nervennetzwerken mit seinen 1010 Neuronen die jedes mit 1.000 bis 10.000 mit anderen Neuronen vernetzt sind, inspiriert.
Die Grundidee eines künstlichen neuronalen Netzes ist dabei, das Eingabeaktivitäten, z.B. ein Eingabemuster wie eine Ziffer, auf eine Eingabeschicht eines neuronalen Netzes trifft und prägt dort eine Aktivierung. Berechnet werden dann die Aktivitätsausbreitung auf die nachfolgenden Schichten des neuronalen Netzes von den Eingabe- zu den Ausgabeneuronen. Wie die Ausbreitung bzw. die Berechnung verläuft hängt vom Verbindungsmuster zwischen den Neuronen ab. Das Lernen verändert diese Verbindungen und ersetzt damit eine Programmierung.
Hinter einem einzelnen Neuron steckt dabei ein mathematisches Modell (gewichtete Summe), das Eingabesignale, die auf Kontaktstellen treffen in jeweilige Kontaktstärken aufschlüsselt und diese aufsummiert. Im zweiten Schritt erfolgt eine nichtlineare Transformation. Unterschiedliche Sättigungswerte (z.B. bei der Ziffernerkennung) werden glatt interpoliert und als Ausgabesignal an nachfolgende Neuronen weitergegeben. Häufig ist ein gewisser Zielwert gewünscht, der mit Hilfe von Lernregeln adaptiert wird. Ein neuronales Netz kann mehrere Schichten aufweisen.
Vor der Nutzung eines neuronalen Netzes zur Bearbeitung einer gegebenen Problemstellung muss es zunächst trainiert werden. Mit Hilfe vorgegebener Lerndaten und Lernregeln werden die Verbindungen der Neuronen im neuronalen Netz gewichtet bis es eine gewisse „intelligente“ Verhaltensweise aufweist. Neuronale Netze ersetzen Programmierung durch Lernen aus Daten.
Deep Learning: Kennzeichnet ein tiefes neuronales Netz, das eine große Anzahl von Neuronen in verschiedenen Schichten von der Eingabe- bis zur Ausgabeschicht umfasst. Ein flaches neuronales Netz weist häufig nur eine oder zwei Schichten auf.
Die nachfolgende Abbildung zeigt eine vereinfachte Darstellung zur Einordnung der Begriffe

Abbildung: Vereinfachte Begriffseinordnung
Mögliche Anwendungsfälle in Unternehmen – Eine Auswahl
Chatbots als virtuelle Assistenten (u.a. Verbesserung in der Kundeninteraktion über textbasierte Dialogsysteme mit denen Chats geführt werden können)
Spracherkennung/-verarbeitung / Sprachassistenzsysteme (u.a. bekannte sind u.a. Siri, Alexa, Cortana, weitere)
Textanalyse (u.a. Spam-Erkennung in E-Mails durch intelligente Filter)
Predictive Maintenance - Hier geht es darum frühzeitig Indikatoren zu erlernen, die voraussichtlich zum Ausfall einer Maschine führen. Eine Maschinenwartung kann dann rechtzeitig erfolgen bevor der Ausfall droht. Ein Austausch von Teilen wird erst dann vorgenommen, wenn es wirklich erforderlich ist und nicht weil ein geplanter Wechselzyklus es verlangt.
Erkennung von Abweichungen vom Normalverhalten (z.B. Erkennung von Störeinflüssen im Betrieb, Anomalie-Detektion, Online-Condition-Monitoring, akustische Überwachung von Maschinen und Produktionsprozessen, etc.)
Bilderkennung/Bildklassifikation (u.a. Mustererkennung, Ausschussreduktion in der Produktion, Gesichtserkennung bei Facebook, Gesichtserkennung für den Zugang zum eigenen Smartphone, etc.)
Autonomes Fahren
Autonome Roboter (Robotic Process Automation – RPA)
Wissensextraktion aus Daten (Mustererkennung aus großen Datenmengen, Big-Data-Analytics)
Erkennen von Mustern in Datenreihen und Vorhersage nächster Werte (z.B. Mustererkennung, Mustererlernung, etc.)
Mögliche Anwendungsgebiete – Eine Auswahl
Prozessautomatisierung: Automatisierung von Fachprozessen (Geschwindigkeit erhöhen, Effizienz steigern, weniger Kosten, Reduktion von Routineaufgaben, etc.)
Industrie 4.0 (u.a. intelligente Automation, adaptive Regelungssysteme, etc.)
Logistik (u.a. Prognosen zur Kundennachfrage zur Einbettung in bestehende Supply-Chain-Prozesse, etc.)
Instandhaltung - Predictive Maintenance statt fester Wartungsintervalle zur Reduktion von Maschinenstillständen und den damit verbundenen Ausfall-/Wartungskosten, etc.)
Medizin - Bildgestützte Diagnoseverfahren (z.B. Automatisierte Hautkrebserkennung, Analyse radiologischer Bilder bzw. weiterer bildgebender medizinischer Diagnoseverfahren, etc.)
Medizin – Genetisches Sequenzing
KI im Personalmanagement (u.a. Recruiting, Skill-Management, automatisiertes Screening/Abgleich von Lebensläufen zur Optimierung der Kandidatenauswahl, etc.)
Datenanalyse zur Mustererkennung in großen Datenmengen (z.B. Anomalie Erkennung, Betrugserkennung/Kreditkartenbetrugserkennung, Aktienmarktanalyse, etc.)
Customer-Relationship-Management - Kundenbedarfe genauer erkennen/Personalisierung von Werbemaßnahmen, Abwanderungstendenzen von Kunden frühzeitig erkennen, etc.)
Textanalyse im Versicherungsbereich - Kontextinformationen bei simplen Versicherungsfällen durch automatisierte Textanalyse und automatisierte Berichtsgenerierung / Antwortschreibengenerierung
Entwicklung neuer Geschäftsmodelle und Services
Vorgehensmodell für KI-Projekte – Maschinelles Lernen
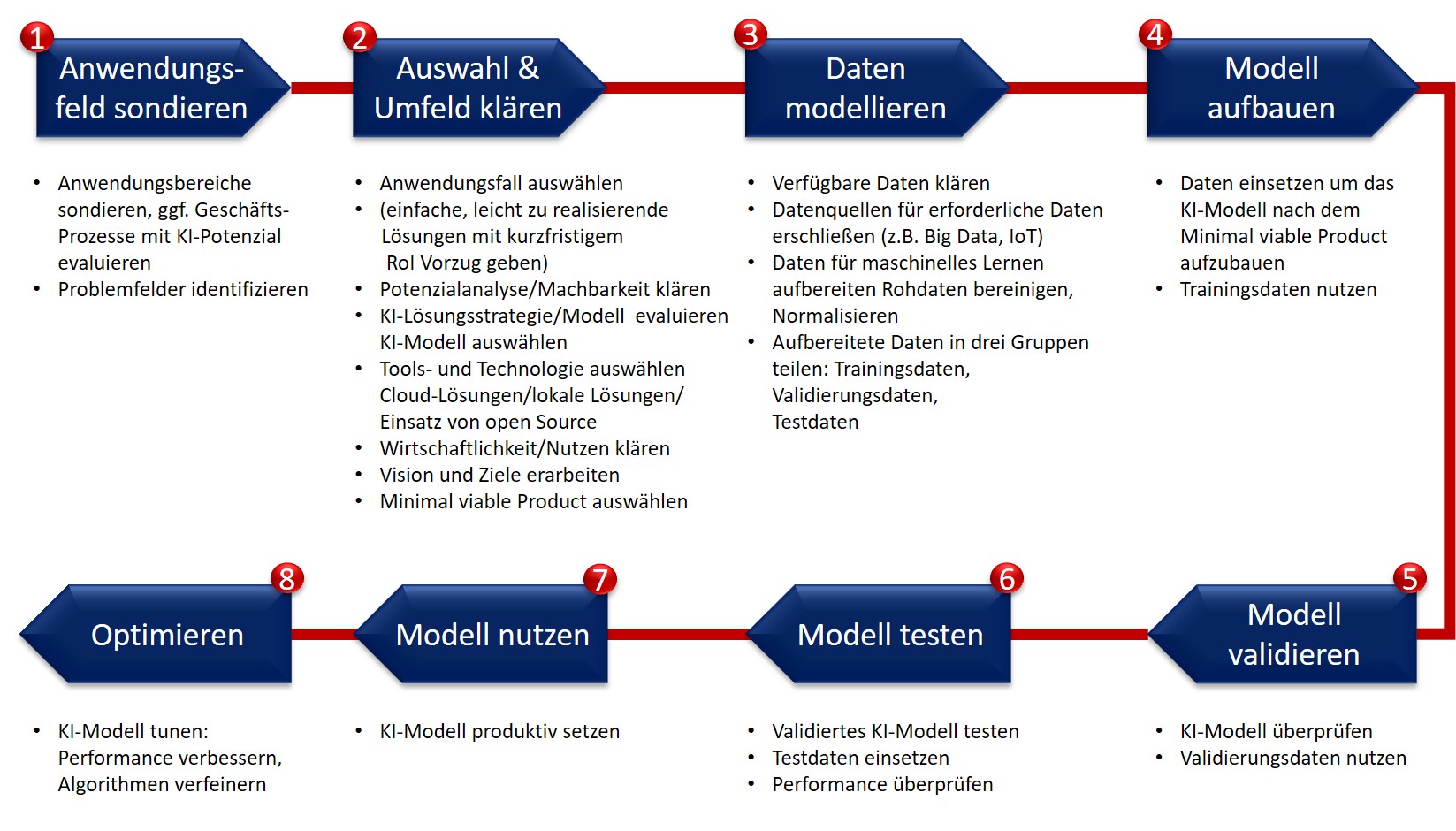
Abbildung: Mögliches Vorgehensmodell im Rahmen von KI-Projekten
Parallel dazu gilt es KI-Expertise im eigenen Unternehmen aufzubauen, Wissen und Fähigkeiten zu entwickeln.
Kritische Erfolgsfaktoren beachten
- KI-Projekte nicht als Technologieprojekte verstehen, sondern aus der Business Perspektive betrachten, keine Prestige-Projekte, klein anfangen mit klarem Anwendernutzen
- Verfügbarkeit von Daten ausreichender Güte (Algorithmen können nur so gut wie die Daten sein) für das Training der KI-Modelle
- Erforderliche Datenquellen erschließen, z.B. über IoT- (Internet of Things) und/oder Big Data Anwendungen
- Verfügbarkeit von Mitarbeitern mit KI-, Datenmanagement-, Business-Intelligence - und-analytic Skills
Projektansatz für KI-Projekt auswählen – agil oder klassisch?
Um einzuschätzen welcher Projektansatz für ein KI-Projekt der geeignete sein könnte, agil (z.B. Scrum) oder klassisch (z.B. PMBOK®-Guide, Prince2 mit Wasserfall-Vorgehen etc.), hilft ein Blick in die Stacey Komplexität-Matrix.

Abbildung Stacy-Matrix
(Weitere Informationen zur Stacey Matrix siehe auch Blog-Artikel „Projektabwicklung - Wann agil, wann klassisch?“)
Die Achsen:
X- Achse: Sicherheit der Technologie meint in diesem Zusammenhang den Bekanntheitsgrad und die Beherrschung der Technologie. So werden i.d.R. sichere Technologien gut verstanden und sicher beherrscht. Bei Technologien mit hoher Unsicherheit, liegen wenig oder gar keine Erfahrungen vor oder deren Verhalten sind schwierig zu prognostizieren.
Y-Achse: Klare Anforderungen sind stabil, im Detail dokumentierbar und bei Lieferung wird genau das erhalten was auch gebraucht wird. Unklare Anforderungen sind dynamisch, nur sehr gering oder gar nicht dokumentierbar und am Ende wird ggf. festgestellt, dass eigentlich etwas anderes gebraucht wird
Während in den Bereichen Simpel und Kompliziert die klassischen Projektansätze eher geeignet sind, wirken im Bereich Komplex andere Mechanismen.
Der Bereich Komplex: Je unklarer die Anforderungen und unsicherer die Technologien werden desto mehr gelangt man in den komplexen Bereich. Ursache-Wirkungsbeziehungen lassen sich nicht prognostizieren und sind erst hinterher einer Analyse wirklich zugänglich. Die Veränderungsdynamik ist hoch. Klassische Project- und Product-Life Cycle mit ihren langfristigen Planungszyklen sind nicht mehr geeignet, da sie auf eine gewisse Stabilität in der Planung sowie Vorhersagbarkeit von Ursache und Wirkung basieren.
Hier bieten sich agile Vorgehensweisen, z.B. Scrum an, die iterativ, inkrementell, adaptiv die Planung und Umsetzung angehen. Nach jedem Sprint wird überlegt, ob sich die Rahmenbedingungen geändert haben und ggf. erfolgen dann umgehend und adaptiv die Anpassungen.
Betrachtet man nun KI-Projekte, so wird offensichtlich, dass bei den KI-Technologien häufig viel Unsicherheiten und wenige Erfahrungen (je nach gewähltem Anwendungsgebiet) damit vorliegen. Auch die Anforderungen sind oftmals nicht stabil, unklar und sehr dynamisch.
Damit kann die als wahrscheinlich erfolgversprechendste Projektabwicklungsmethodik nur eine agile Vorgehensweise sein. Hier z.B. Scrum, wie nachfolgend dargestellt.
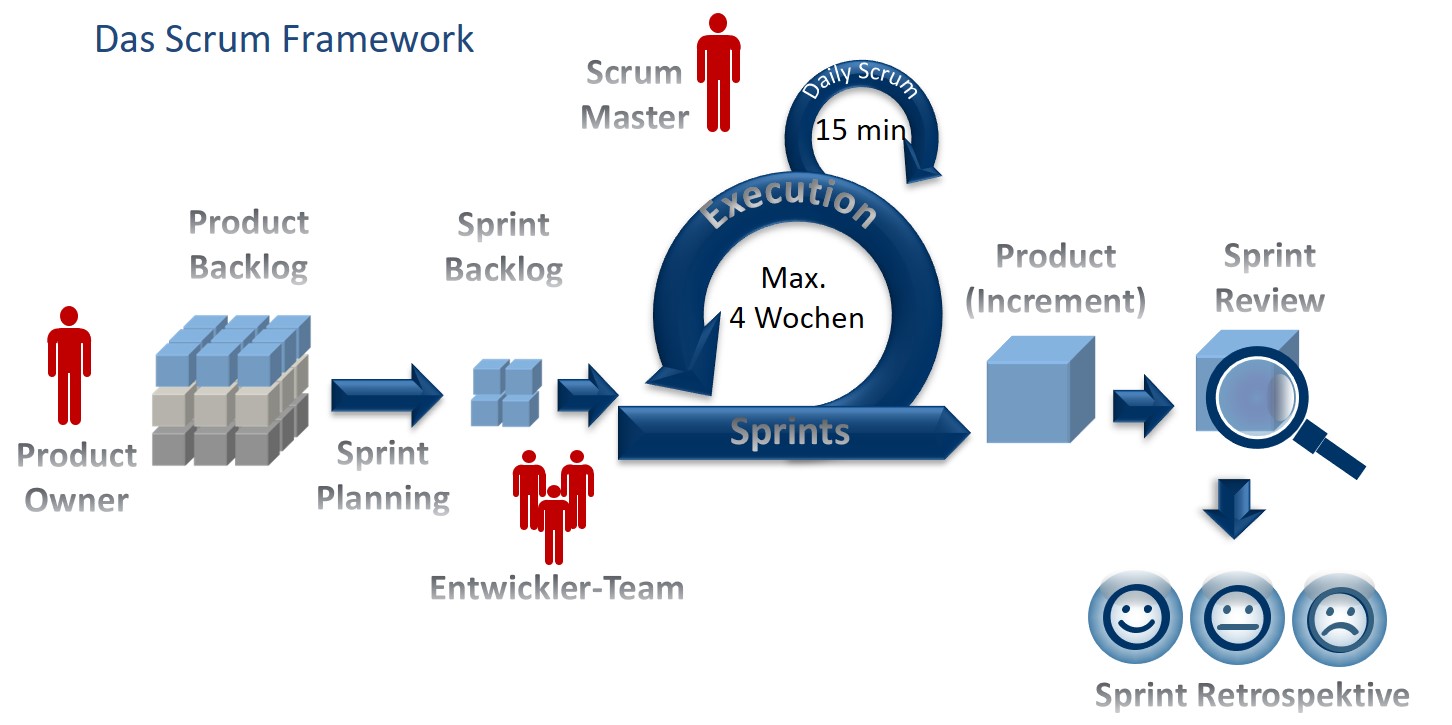
Abbildung Scrum Framework
Der Product Owner, eine der 3 Rollen in Scrum, ist für den wirtschaftlichen Erfolg des Produktes verantwortlich. Er startet die Produktentwicklung mit einer motivierenden Produktvision.
Alle relevanten Stakeholder werden in die Erstellung der Produktvision und in die Erhebung der Anforderungen eingebunden.
Anforderungen werden vom Product Owner, abgeleitet von der Produktvision, in einem Verzeichnis, dem Product Backlog gesammelt und priorisiert. Er ist der Eigner und Gestalter des Backlogs.
Der Product Owner vereinbart im Sprint planning zusammen mit dem Entwickler-Team, welche Anforderungen aus dem Product Backlog in den Sprint übernommen werden sollen. Diese Anforderungen werden dann in den Sprint Backlog übernommen.
Mit der Übernahme in den Sprint Backlog verpflichten sich beide, Product Owner und Entwickler-Team, auf die Umsetzung dieser Anforderungen im anstehenden Sprint.
Das Entwicklerteam schätzt dabei in Eigenregie ab, wieviel es im anstehenden Sprint abarbeiten kann.
Die Umsetzung der Anforderungen erfolgt in einem Sprint. Das ist ein Entwicklungszyklus mit einer festen Dauer. Die feste Dauer ermöglicht eine gute Vergleichbarkeit untereinander. Aus der Umsetzungsgeschwindigkeit des Teams innerhalb eines Sprints kann auf die Umsetzungsdauer der nächsten Sprints prognostiziert werden.
Sprints folgen unmittelbar aufeinander. Während eines Sprints arbeitet das Entwickler-Team störungsfrei, ohne Eingriffe von außen. Das heißt keine neuen Anforderungen oder Änderungen während eines Sprints! Die laufen dann in den nächsten Sprint.
Das daily scrum dient dem Abgleich zum aktuellen Status und auch der Einsatzplanung für den Tag. Es findet jeden Tag für max. 15 min, immer am gleichen Ort und stehend (stand-up) statt.
Am Ende des Sprints findet das Sprint Review statt. Im Sprint review wird das Produkt(-inkrement) überprüft und ggf. das Product Backlog angepasst. Das Scrum Team und die Stakeholder befassen sich in diesem Meeting mit den Ergebnissen und geben ihr Feedback.
Die umgesetzten Anforderungen sollten über den Sprint zu einem potenziell auslieferbaren Produkt(-inkrement) führen. Häufig werden im Review weitere Anforderungen eingebracht, die der Product Owner in den Backlog aufnimmt.
Im Anschluss an den Sprint Review, der sich mit dem Produkt befasst, findet die Sprint Retrospektive statt. Hier befasst sich das Scrum Team mit Prozess. Was ist gut gelaufen und sollte in die nächsten Sprints übernommen werden, was ist nicht so gut gelaufen und sollte verbessert werden.
Das ist ein kontinuierlicher Verbesserungsprozess der zu ständigem Lernen führen soll.
Ist die Retrospektive abgeschlossen, geht es direkt in den nächsten Sprint.
Vorteile in diesem Kontext:
- Adaptive und inkrementelle Vorgehensweise
- Dynamische Anpassung des Vorhabenumfangs immer möglich
- Häufige Rückkopplung zwischen Scrum-Team und Anwendern/Kunden
Vom Aufsetzen eines KI-Projekts bis zum Abschluss
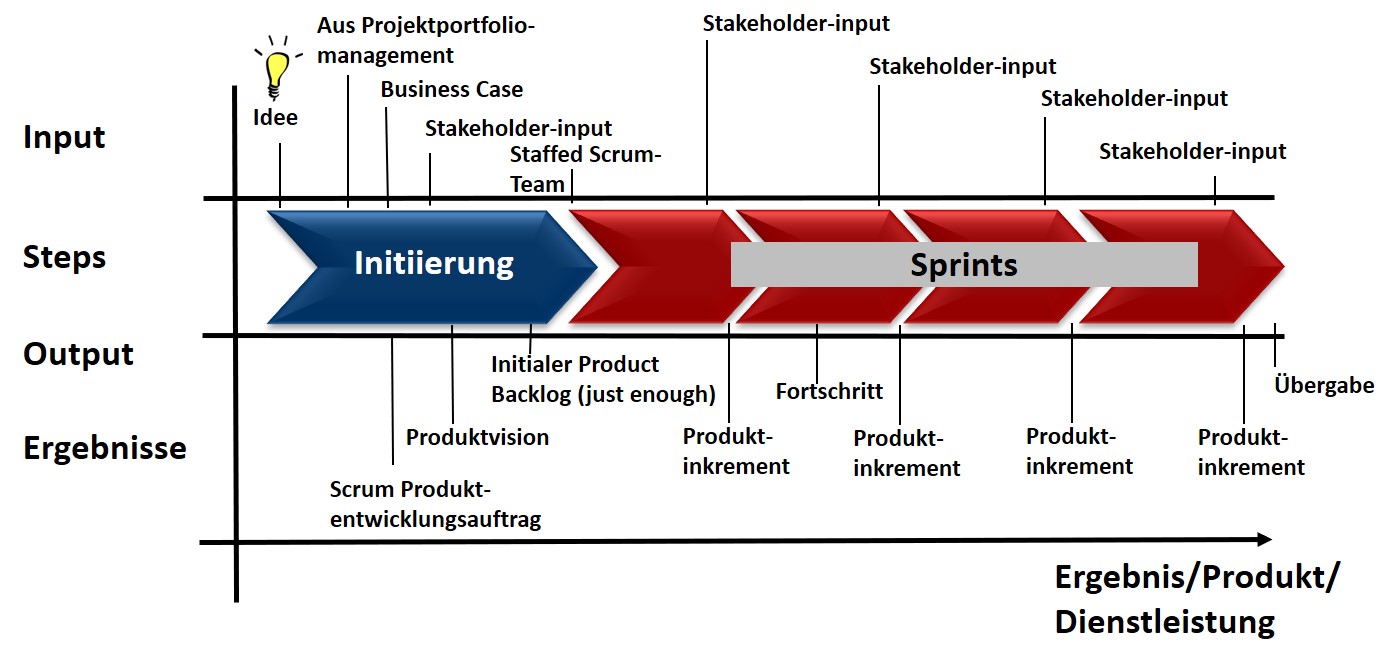
Abbildung Von der Idee zum Produkt mit Scrum
Verfügbare KI-Plattformen, KI-Tools und KI-Technologien
Proprietäre KI-Tools (eine kleine Auswahl)
Open AI mit ChatGPT, Dalle-E, Sora https://openai.com/
ChatGPT Plugins https://www.whatplugin.ai/plugins/taskml
Microsoft Copilot https://copilot.microsoft.com/
Google DeepMind https://deepmind.google/technologies/gemini/#introduction
Open Release of Grok-1 https://x.ai/blog
Große Cloudanbieter wie Amazon Web Services, IBM, Google und Microsoft haben zwischenzeitlich Lösungen und Services geschaffen, die es Entwickler ermöglichen ohne spezielles Machine-Learning Know-how intelligente Anwendungen zu bauen.
Amazon Web Services Maschinelles Lernen und Deep Learning https://aws.amazon.com/de/machine-learning/what-is-ai/
IBM Watson als innovative AI-Plattform für Unternehmen https://www.ibm.com/watson/de-de/
Microsoft AI – KI Plattform https://www.microsoft.com/de-de/ai/ai-platform
Google Cloud AI – Cloud AutoML https://cloud.google.com/automl/
Open Source KI-Tools (eine kleine Auswahl)
Machine Learning – Tensorflow https://www.tensorflow.org/
Data-Mining-Software zum Analysieren großer Datenbestände – Rapidminer 5.3 https://www.heise.de/download/product/rapidminer-46252
Deep-Learning-Framework Caffe2, now PyTorch https://pytorch.org/
Data mining, Datenanalyse, Machine Learning in Python scikit-learn https://scikit-learn.org/stable/
Machine Learning – Apache Spark http://spark.apache.org/
Fazit
KI ist in der Wirtschaft und bei vielen Menschen angekommen. Obwohl vielfach noch unübersichtlich mit z.T. schwer einzuschätzenden künftigen Chancen und Auswirkungen bietet KI bereits erhebliches Potenzial. Die vielen bereits existierenden Anwendungen belegen es.
Die Verfügbarkeit von Web Services und Plattformen wie z.B. Amazon Web Services erfordern keine hohen Anfangsinvestitionen in Hardware und Software. Auch der Entwicklungsaufwand kann sich reduzieren.
In KI-Projekten ist hinsichtlich der Anforderungen mit einiger Dynamik zu rechnen. Oftmals liegen bei Unternehmen wenig oder kein Wissen und Erfahrungen mit KI-Technologien vor. Daher wird eine agile Vorgehensweise, die ein iteratives, inkrementelles und adaptives Vorgehen, wie sie z.B. bei Scrum vorliegt, für die Umsetzung empfohlen.
Wichtig für ein KI-Projekt für Einsteiger ist zunächst einen Anwendungsfall auszuwählen, der klaren Nutzen und RoI verspricht, vom Umfang her überschaubar und damit rasch umsetzbar ist und es erlaubt Know-how und Erfahrung mit dieser Technologie im eigenen Unternehmen zu aufzubauen.
Interessante Links und Hinweise um auf dem laufenden zu bleiben
Opena AI mit ChatGPT (KI bot), Dalle-E (Text to image), Sora (Text to Video) und mehr https://openai.com/
Hugging Face- Hugging Face, Inc. ist ein US-amerikanisches Unternehmen, das Werkzeuge für die Erstellung von Anwendungen mit maschinellem Lernen entwickelt. - https://huggingface.co/
Deutsches Forschungsinstitut für künstliche Intelligenz: https://www.dfki.de/web/
Maschinelles Lernen Was es ist und was man darüber wissen sollte https://www.sas.com/de_ch/insights/analytics/machine-learning.html
Computerwoche Voice of digital: https://www.computerwoche.de/k/kuenstliche-intelligenz-artificial-intelligence,3544